并发控制
1. 锁机制
1.1 模式
| 类型 | 拥有 | 功能 | 适用 |
|---|---|---|---|
| 排他锁(Exclusive Lock, X-Lock) | 只允许一个事务拥有数据的排他锁 | 拥有排他锁的事务可以对数据进行读和写操作,同时禁止其他事务对该数据进行任何操作 | 需要修改数据,如UPDATE |
| 共享锁(Shared Lock, S-Lock) | 允许多个事务拥有同一数据的共享锁 | 拥有共享锁的多个事务都可以读取数据,但是任何事务都不能对数据进行更改 | 只需要读取数据,如SELECT |
相容性
- 被共享锁锁住的数据,事务可以申请该数据的共享锁,但是不能申请该数据的排他锁
- 被排他锁锁住的数据,事务不能申请该数据的任何锁

锁的授予流程
- 事务向并发控制管理器发出锁请求
lock-X/S(data) - 并发控制管理器根据规则决定是否授予锁
grant-X/S(T,data) - 如果成功获取锁,事务继续执行,否则事务被迫阻塞等待
- 事务执行完毕或者不再需要对数据加锁,则释放锁
unlock-X/S(data)

1.2 问题
- 死锁(deadline):多个事务彼此等待对方的锁释放,形成了闭合的等待链,从而陷入了无限阻塞的状态(如下图,T4等待T3释放B上的X锁,T3等待T4释放A上的S锁)
- 饥饿(starvation):某个数据一直被申请共享锁,导致某个对该数据申请排他锁的事务陷入了长期等待的状态
- 破坏冲突可串行化:某些指令等待时间过长,导致调度的冲突操作顺序与某种串行调度的冲突操作顺序不一致

1.3 封锁协议
封锁点(lock point):调度中事务获得最后一个锁的位置,标志着事务从增长阶段进入缩减阶段
一旦事务进入缩减阶段,就只能释放锁,不能再获取锁,即无法返回增长阶段
| 协议 | 定义 | 性质 |
|---|---|---|
| 简单封锁协议 | 事务在访问数据项之前加锁,在操作完成后立即解锁 | 简单,但可能导致各种问题 |
| 两阶段封锁协议(2PL) | 在增长阶段事务只能获取锁,在缩减阶段事务只能释放锁 | 保证冲突可串行化,但可能导致死锁 |
| 严格两阶段封锁协议(Strict 2PL) | 在2PL的基础上,要求排他锁必须在事务提交或回滚后才能释放 | 保证冲突可串行化,避免了级联回滚 |
| 强两阶段封锁协议(Rigorous 2PL) | 在2PL的基础上,要求排他锁和共享锁必须在事务提交或回滚后才能释放 | 保证冲突可串行化,避免了级联回滚 |
| 带锁转换的两阶段封锁协议(Lock Conversions) | 允许在增长阶段将共享锁升级为排他锁,允许在缩减阶段将排他锁降级为共享锁 | 提高了锁的灵活性,减少了锁的冲突 |
2PL的意义:封锁点顺序能够反映事务的依赖关系,与某种串行调度的事务执行顺序一致,保证了调度的冲突可串行化
1.4 锁表
锁表:以数据项标识为键的哈希表,每个键对应一个链表,链表连接了若干数据项,每个数据项又对应一个事务链表,包含以下信息
- 提出锁请求的事务
- 事务请求的锁类型
- 锁被授予还是处于等待
锁表的操作
- 加锁:在对应数据项的链表末尾增加一条新的请求记录,如果请求的锁模式与当前授予的锁模式兼容,则立即授予锁,并标记为授予状态,如果不兼容,则将锁请求标记为等待状态
- 解锁:从对应数据项的链表中删除事务的请求记录,然后检查链表中随后的请求记录,判断是否可以授予锁
- 事务中止:会删除该事务所有的持有锁记录和等待锁记录,然后检查链表中随后的请求记录,判断是否可以授予锁

1.5 树型协议
数据库图:是一个有向无环图(DAG),用来表示数据项之间的部分顺序约束关系
- 节点代表数据库中的数据项
- 有向边意味着如果一个事务访问了和,它必须先访问,然后才能访问
- 可以选择一个没有入边的节点作为树的根节点,将有向无环图转换为树

规则
- 事务只能对数据项加排他锁 -> 所有数据访问都以写操作为主
- 事务的首次封锁可以在任何数据项上进行 -> 没有固定的起点限制
- 事务对一个数据项Q加锁的前提是事务当前持有Q的父节点的锁 -> 事务必须按树自顶向下的顺序访问数据项
- 事务对数据项解锁可以随时进行 -> 不局限于两阶段,没有扩展阶段和收缩阶段的限制
- 一个数据项被T加锁并解锁之后,T不能随后再对该数据项加锁 -> 确保事务只访问一次每个数据项

性质
- 优点:保证了冲突可串行化,不会产生死锁,可以随时解锁不需要再访问的的数据项
- 缺点:不保证可恢复性,无法避免级联回滚,需要给根本不访问的父亲数据项加锁来访问子数据项,不支持动态顺序
2. 死锁处理
2.1 死锁避免
| 策略 | 定义 | 缺点 |
|---|---|---|
| 一次性封锁 | 在每个事务开始执行之前必须封锁它所需要的全部数据项 | 降低并发性 |
| 优先级封锁 | 为所有数据项设定一个固定的次序/优先级,只能按照次序来封锁数据项 | 灵活性受限 |
| 等待死亡/自杀 | 新事务请求一个被老事务持有的锁,则新事务会被回滚 | 产生频繁或不必要的回滚 |
| 伤害等待/他杀 | 老事务请求一个被新事务持有的锁,则新事务会被回滚 | 产生频繁或不必要的回滚 |
| 超时 | 申请锁的事务至多等待一段指定的时间,否则会自动回滚并重启 | 无法区分死锁和长等待,需要合理设置超时时间 |
最简单的策略就是一次性封锁和锁超时,但由于前者会破坏并发性,因此实际情况下很少使用,而后者通常作为一种辅助配合其他策略使用
2.2 死锁检测与恢复
等待图:顶点集是事务集合,边Ti->Tj表示事务Ti正在等待事务Tj释放封锁的数据项
死锁检测:系统维护等待图,并周期性地在等待图中执行搜索环路算法,当且仅当等待图中包含环路时,系统中存在死锁

死锁恢复
- 根据以下代价因素,来选择破解环路需要牺牲/回滚哪一个或哪一些事务
- 事务已经执行了多久,还需要执行多久
- 事务当前封锁了多少数据项,事务还需要封锁多少数据项
- 回滚会牵扯到多少个事务需要级联回滚
- 事务的优先级
- 不回滚整个事务,而是只回滚导致死锁的部分操作
- 防止有些事务总是被牺牲从而长时间无法执行
3. 多粒度
多粒度:数据项可以指代不同层次的数据,其中最粗粒度为整个数据库,最细粒度为一个元组/记录,粒度越粗,锁的范围越大,事务可以一次性锁住更多数据
粒度控制:如果事务显式对粗粒度封锁,那么事务会隐式对其下细粒度也封锁

意向锁(intention lock):当事务需要给某个细粒度节点显式加锁前,他会给该节点的所有祖先节点都加上意向锁,因此如果某个节点存在意向锁,就代表他的某个后代节点存在该锁,从而避免在给粗粒度节点加锁时遍历全树来检查是否可以封锁
意向锁只用于声明某个事务的意图,不会实际锁住数据项
多粒度封锁协议
- 加锁顺序必须从根节点开始,按照自顶向下的顺序加锁
- 解锁顺序必须按照自底向上的顺序加锁
- 两阶段封锁,即一旦开始解锁就不能再加锁
- 只有拥有父节点的IX或IS,才能对子节点加S或IS
- 只有拥有父节点的IX或SIX,才能对子节点加X、SIX或IX
- 锁必须满足相容性矩阵

4. 数据库操作
4.1 插入和删除
之前一直聚焦于read和write,相当于select和update,现在聚焦于insert和delete
冲突情况
- 删除数据项之后,不能对该数据项进行select、update和delete
- 插入数据项之前,不能对该数据项进行select、update和delete
- 不存在数据项,则不能进行delete
- 已存在数据项,则不能进行insert
锁规则
- 在对某个数据项执行删除操作之前,事务必须获得该数据项的排他锁
- 当事务向数据库插入新元组时,系统会自动为该新元组分配一个排他锁,并且在提交时才解锁
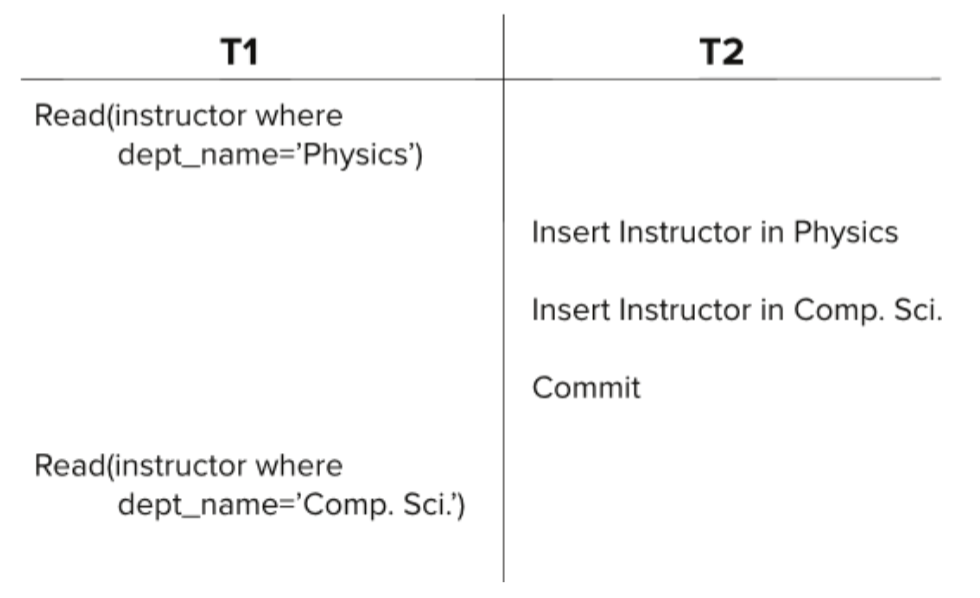
4.2 谓词读
谓词读(Predicate Read):实际上就是带有where条件的select操作
幻读(Phantom Read):谓词读期间,其他事务对查询范围内的数据进行了插入、更新和删除,导致查询结果的记录数发生了变化
- 基于信息:给所有具有谓词信息的数据项加共享锁
- 基于索引:利用索引查询,给所有索引叶节点加共享锁
锁定信息或索引不会与锁定数据项冲突