数据存储结构
1. 数据的组织方式
记录(record)/ 元组(tuple):是数据库中的最小逻辑单位,对应于数据库中的一行,由多个字段组成
块(block):是数据在磁盘上存储和管理的最小单位,每个块包含多条记录
文件(file):是数据在磁盘上存储和管理的最高级别的物理结构,每个文件包含多个块
每条记录必须被完全包含在单个块中,也就是说,不存在一个记录的部分字段在一个块,剩余字段在另一个块
2. 记录的组织方式
2.1 定长记录
定义:每条记录的长度都是固定的,可以存块长度整除记录长度个记录
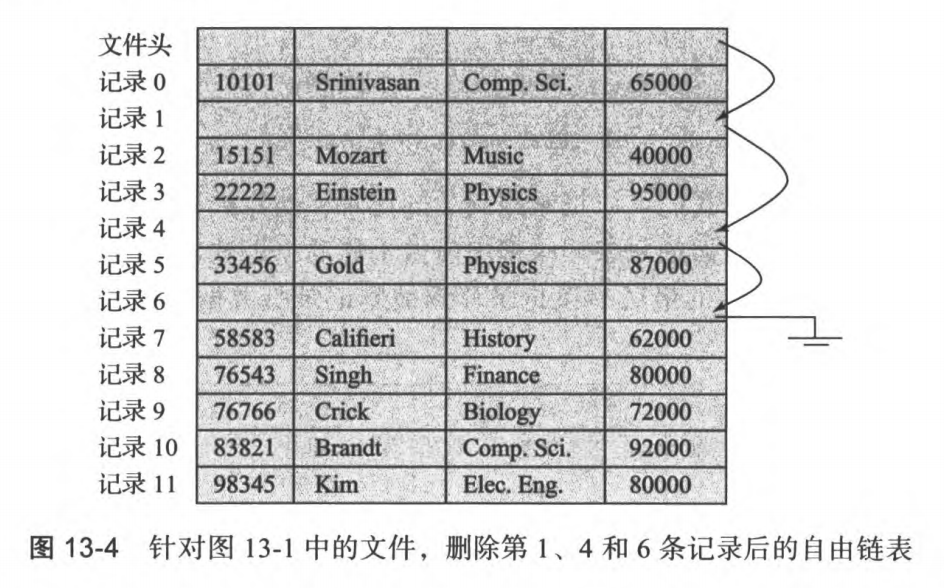
删除记录方法
- 将被删除记录的位置之后的所有记录都向前移动一步
- 只将最后一条记录移动到被删记录的位置
- 从文件头开始,用一个指针指向距离当前位置最近的空闲记录空间,形成自由链表
2.2 变长记录
变长记录的结构:用定长的存储空间记录变长数据的信息(偏移量,长度)
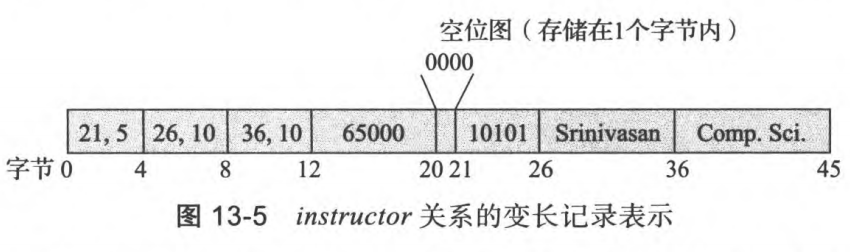
存储变长记录的块结构
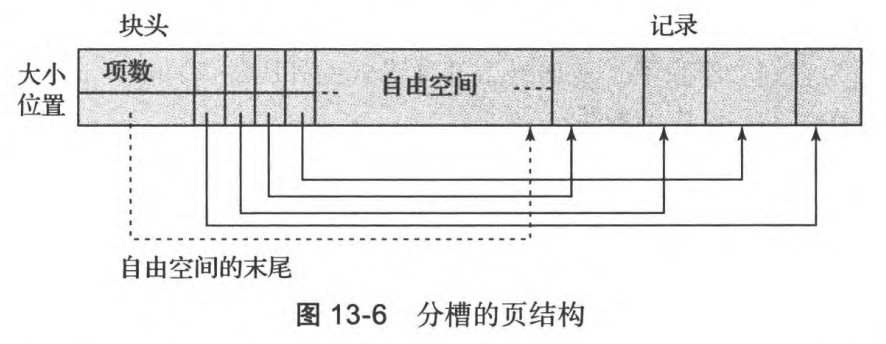
- 块头:当前存储的记录数量,自由空间的末尾位置,由每条记录的起始位置和大小组成的数组
- 自由空间:是一块连续的、空闲的存储空间
- 记录空间:连续存储变长记录
- 插入:从自由空间的末尾插入,并将记录的信息添加到块头中
- 删除:将删除记录位置之前的所有记录向后移动,并修改自由空间末尾指针
3. 文件的组织方式
3.1 堆
定义:数据以无序的方式存储在文件中
插入:新记录直接追加到文件的末尾
删除:记录被标记为“无效”,但物理空间不会被立即回收,会产生空间碎片
特性:插入删除高效、查询低效、空间利用率低
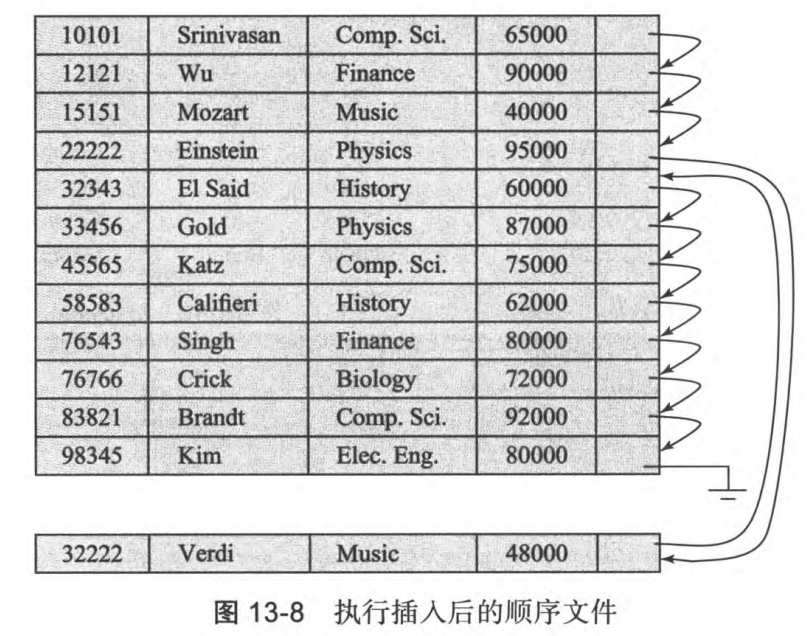
3.2 顺序
定义:根据搜索码,将记录按顺序存储在文件中,每个记录都维护一个指针,每个指针都指向按搜索码顺序排列的下一条记录
插入:先将记录放到一个空闲空间中,然后找到位于待记录顺序码之前和之后的记录,调整指针插入新纪录
删除:需要按顺序将上一个数据的指针指向下一个数据
特性:查询高效、插入删除低效、空间利用率高
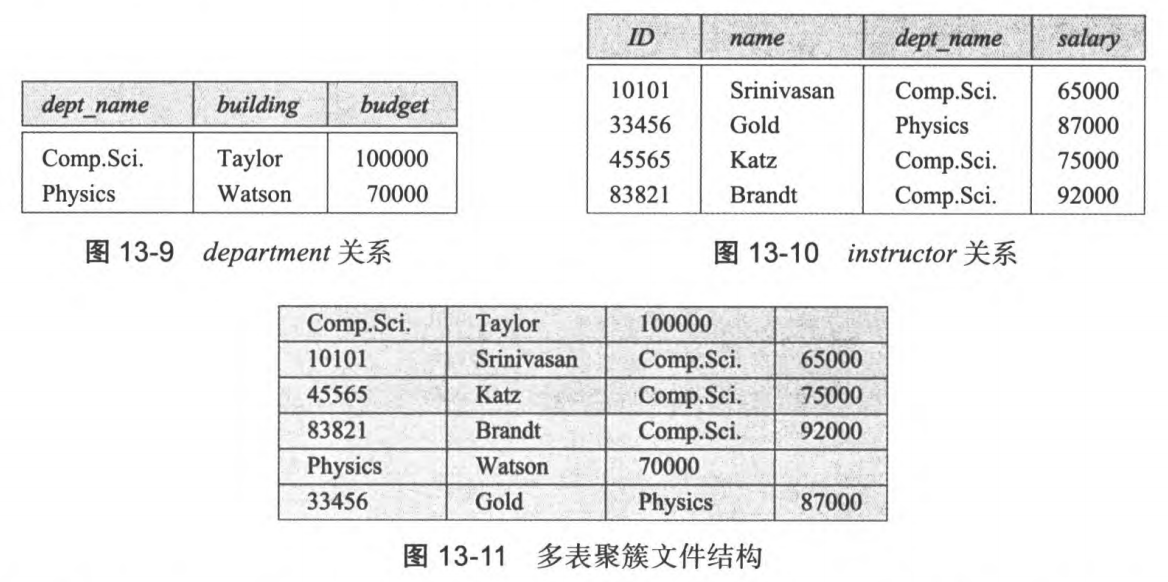
3.3 多表聚簇
定义:根据聚簇码,将多个相关联的表的记录合并存储在文件中
特性:适合于执行大量的连接查询,但是聚簇维护的成本很大
3.4 哈希
定义:通过哈希函数将记录分配到多个分区,然后将不同分区的数据存储在不同文件中
特性:
- 支持数据归档:将较新的数据放到SSD以支持快速访问,将较旧的数据放到磁盘上
- 提高管理灵活性:可以独立地对每个分区进行维护
- 提高查询效率:可以只检索某个分区的数据,而不是加载整张大表
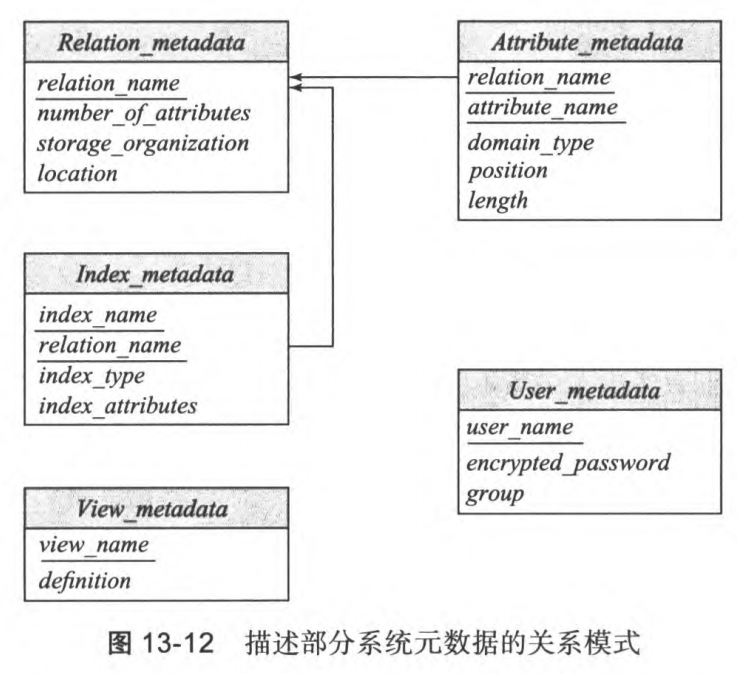
3. 数据字典
定义:集中存储数据库元数据的系统表,包含了数据库中所有对象的定义和描述信息
- 表的结构(表名、列名、数据类型、约束等)
- 索引的定义(索引名、索引类型、索引列等)
- 视图的定义(视图名、视图查询等)
- 用户权限(用户、角色、权限等)
- 存储过程和触发器的定义
存储位置
- 内存数据字典:数据库启动时,将数据字典的元数据加载到内存中,以便快速访问和管理
- 磁盘数据字典:数据字典的元数据以表的形式存储在磁盘上
4. 数据库缓冲区
4.1 缓冲区管理器功能
定义:是内存中的一块区域,用于临时存储从磁盘读取的数据块或即将写入磁盘的数据块,从而减少磁盘I/O操作,提供数据的一致性管理和并发控制
- 替换:当缓冲区没有剩余空间时,需要使用替换策略决定哪个块需要被移出
- 钉住:在一个进程读取或写入缓冲块时,钉住该块以确保该块不会被其他进程替换
- 上锁:在一个进程读取或写入缓冲块时,上锁该块以确保该块不会被其他进程使用
- 读:检查缓冲区中是否已经缓存了所需读的数据块
- 写:先将修改的数据写入缓冲区并标记为脏页,然后根据策略写回磁盘来保证数据一致性
4.2 写出策略
| 写出策略 | 写入时机 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 立即写出 | 每次操作后立即写入磁盘 | 确保数据实时持久化,避免数据丢失 | 磁盘I/O开销大,影响性能 | 高一致性要求的系统,如金融系统 |
| 延迟写出 | 数据先保存在内存,稍后批量写入 | 减少频繁的磁盘I/O,提升性能 | 数据可能丢失,系统崩溃时有风险 | 高性能要求且数据丢失可以容忍的系统 |
| 强制写出 | 事务提交时强制写入磁盘 | 确保数据持久性,一致性强 | 性能开销大,影响系统吞吐量 | 需要严格保证数据一致性的系统 |
4.3 替换策略
| 方法 | 最近最少使用(LRU) | 最近最常使用(MRU) | 最不经常使用(LFU) |
|---|---|---|---|
| 淘汰依据 | 选择时间戳最小的 | 选择时间戳最大的 | 选择访问次数最少的 |
| 适用场景 | 局部性较强的数据 | 一次性访问的数据 | 局部性较强的数据 |
| 缺点 | 可能会替换掉需要长期保留数据 | 可能会替换掉仍然需要被访问的数据 | 可能会替换掉偶尔访问但很重要的数据 |
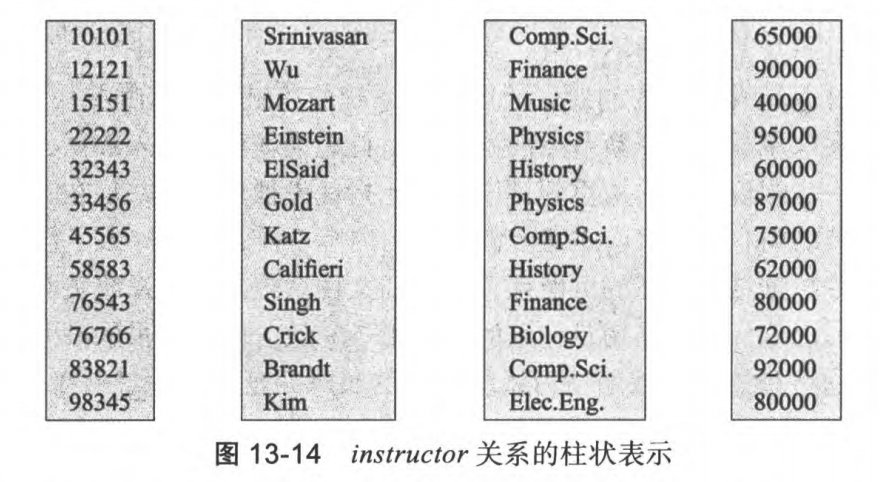
5. 面向列的存储
定义:每个属性都被单独存储在一个单独的文件中,来自相邻元组的属性值存储在文件中相邻的位置上,也被称为柱状存储
优势
- 减少I/O:面向列存储使得数据库只加载查询所需的列,避免了读取整行数据的开销,减少了不必要的I/O操作
- 提高CPU缓存性能:由于同一列的数据存储在一起,提高了数据访问的局部性,使得CPU缓存的利用率更高,从而加速数据的访问速度
- 提高压缩效率:同一列中的数据类型相同,数据具有较高的相似性,这使得列存储能够使用更高效的压缩算法,节省存储空间
- 向量处理:面向列的存储非常适合SIMD等向量化处理,可以高效地对一列数据进行并行计算,显著提升计算性能
缺点:
- 元组重构的代价大:重构完整的行数据时,必须从多个列中读取数据,增加了重构的复杂性和I/O成本
- 元组删除和更新的代价大:需要修改多个列的数据块,且可能涉及到数据重排或压缩,这会导致更高的写操作代价
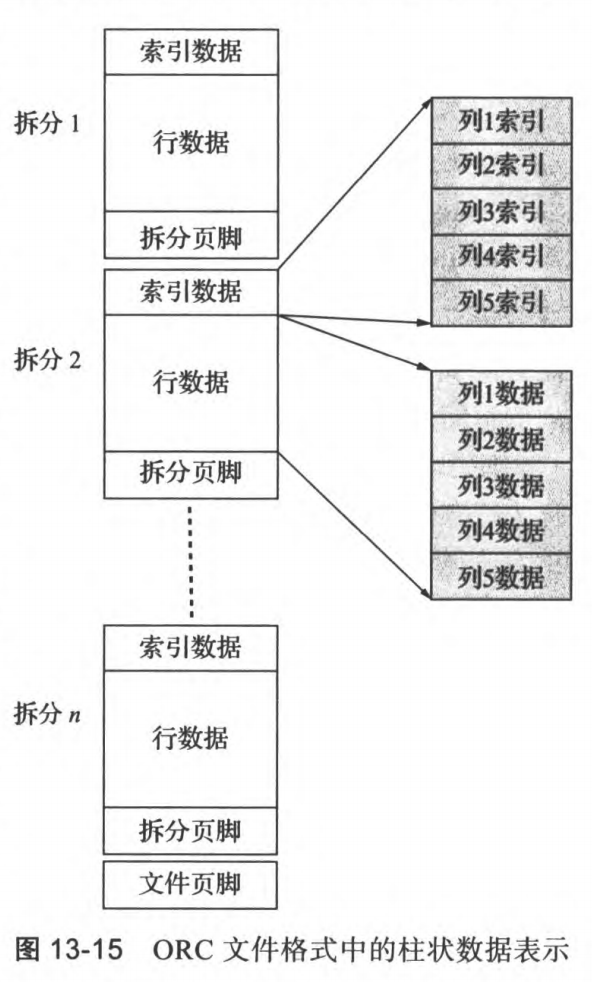
行式存储适合事务处理,列式存储适合数据分析
